Path planning under uncertainty
Date: 2025
When medical devices like steerable needles navigate through tissue, they don't follow perfect paths. Small variations in tissue properties and control inputs cause the needle to deviate from its intended trajectory. This project tackles that challenge by implementing a probabilistic planner that solves for this uncertainty. Rather than computing a single path that the needle is unlikely to follow exactly, we generate a policy that tells the needle what to do from any position it might end up in.
In this project, the Stochastic Motion Roadmap (SMR) algorithm was implemented in C++ using OMPL and tested in two 2D environments with varying complexity. The results show that as we sample more states (n), the planner's success rate improves dramatically, reaching up to 81% in challenging scenarios filled with obstacles.
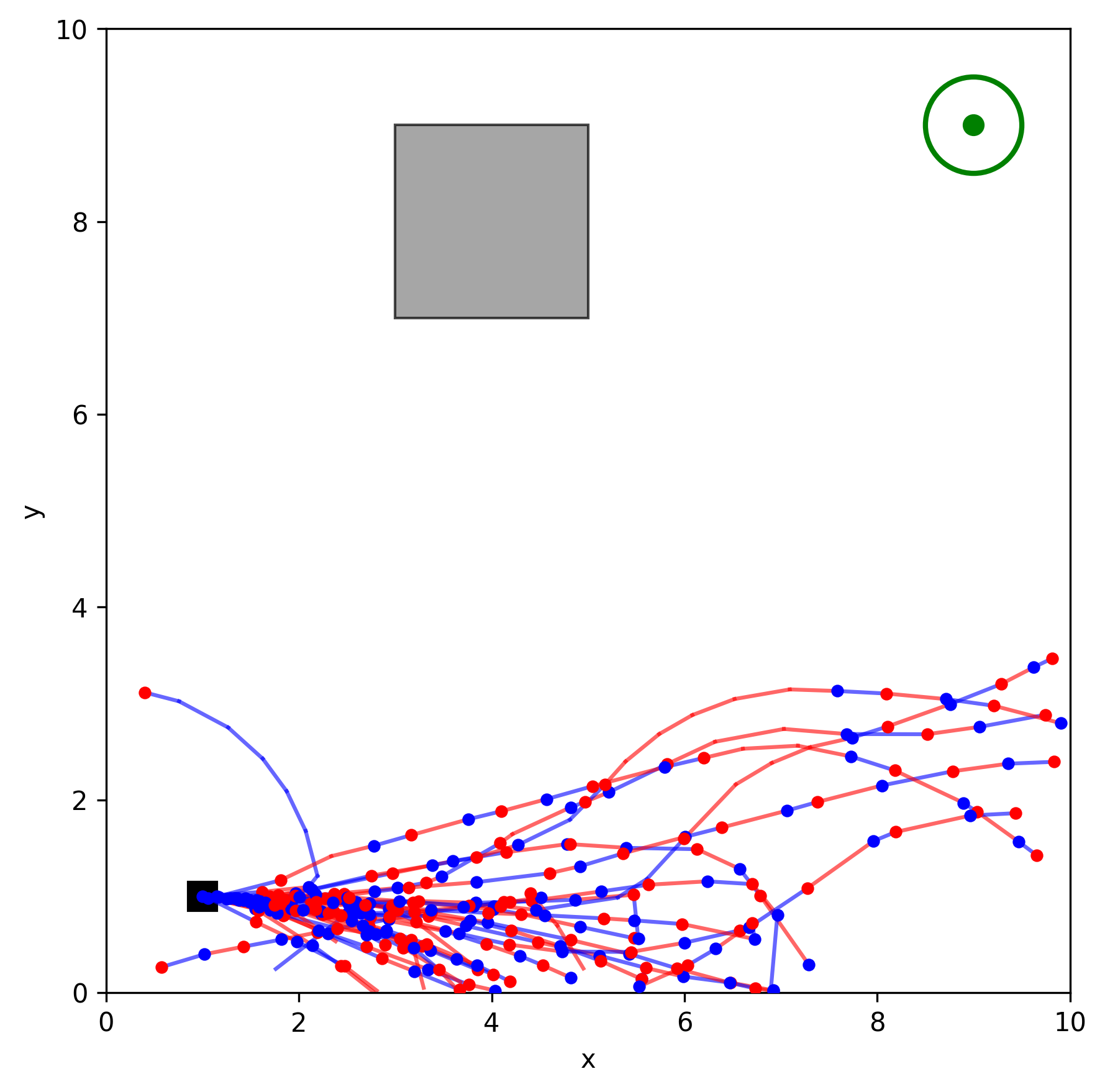
Figure 1. Simple environment, n = 400 .
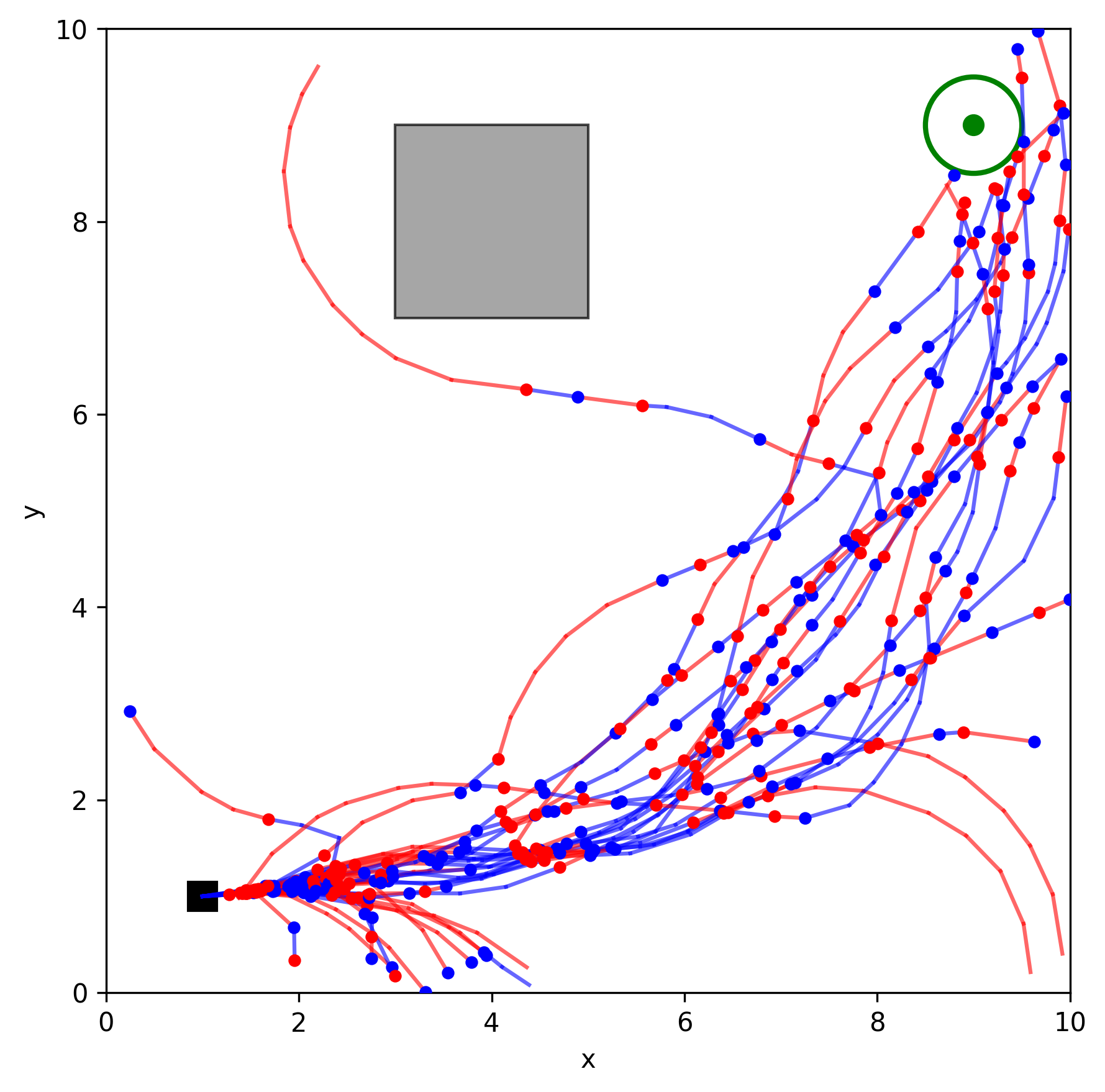
Figure 2. Simple environment, n = 1000 .
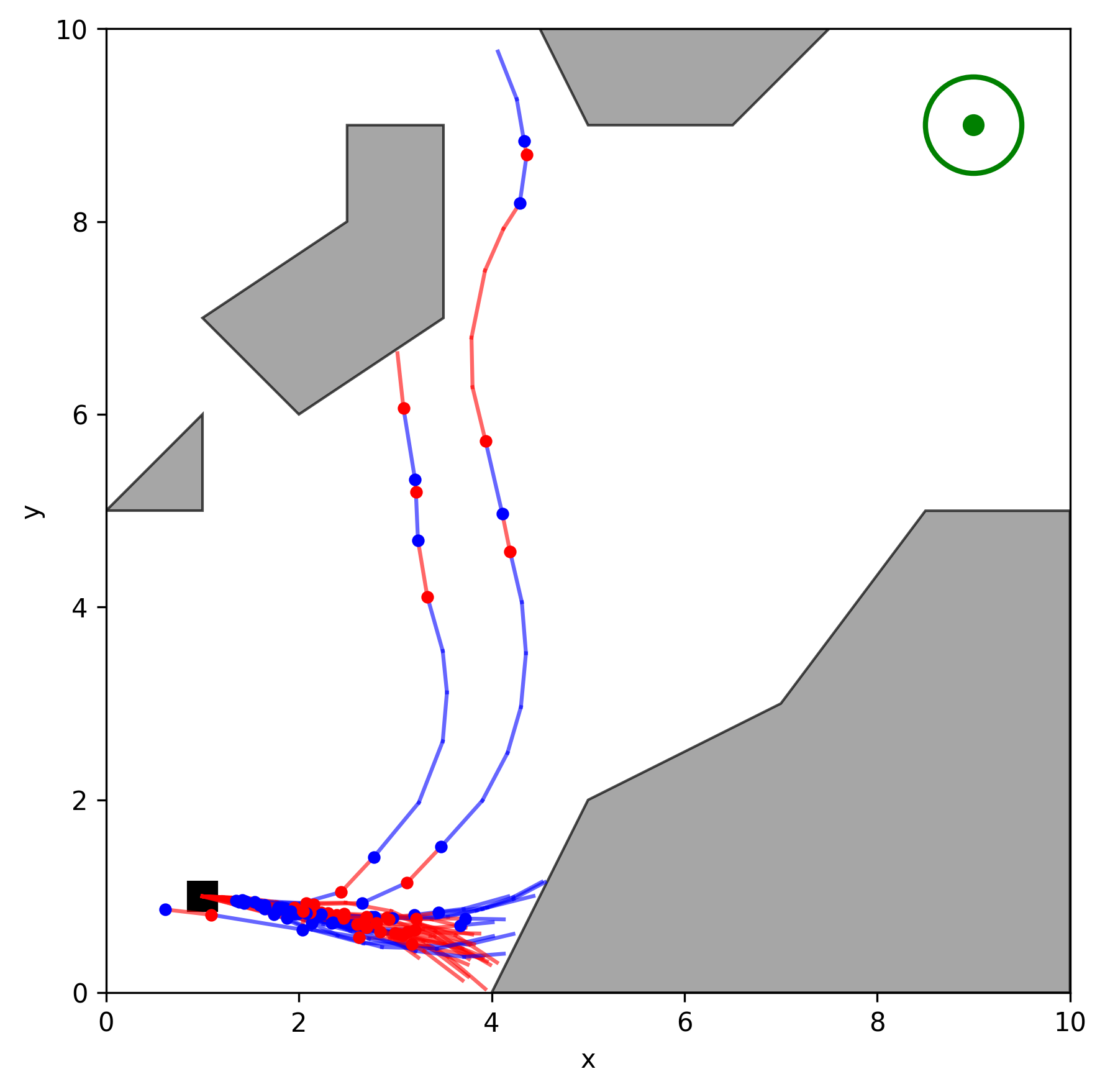
Figure 3. Medium environment, n = 400.
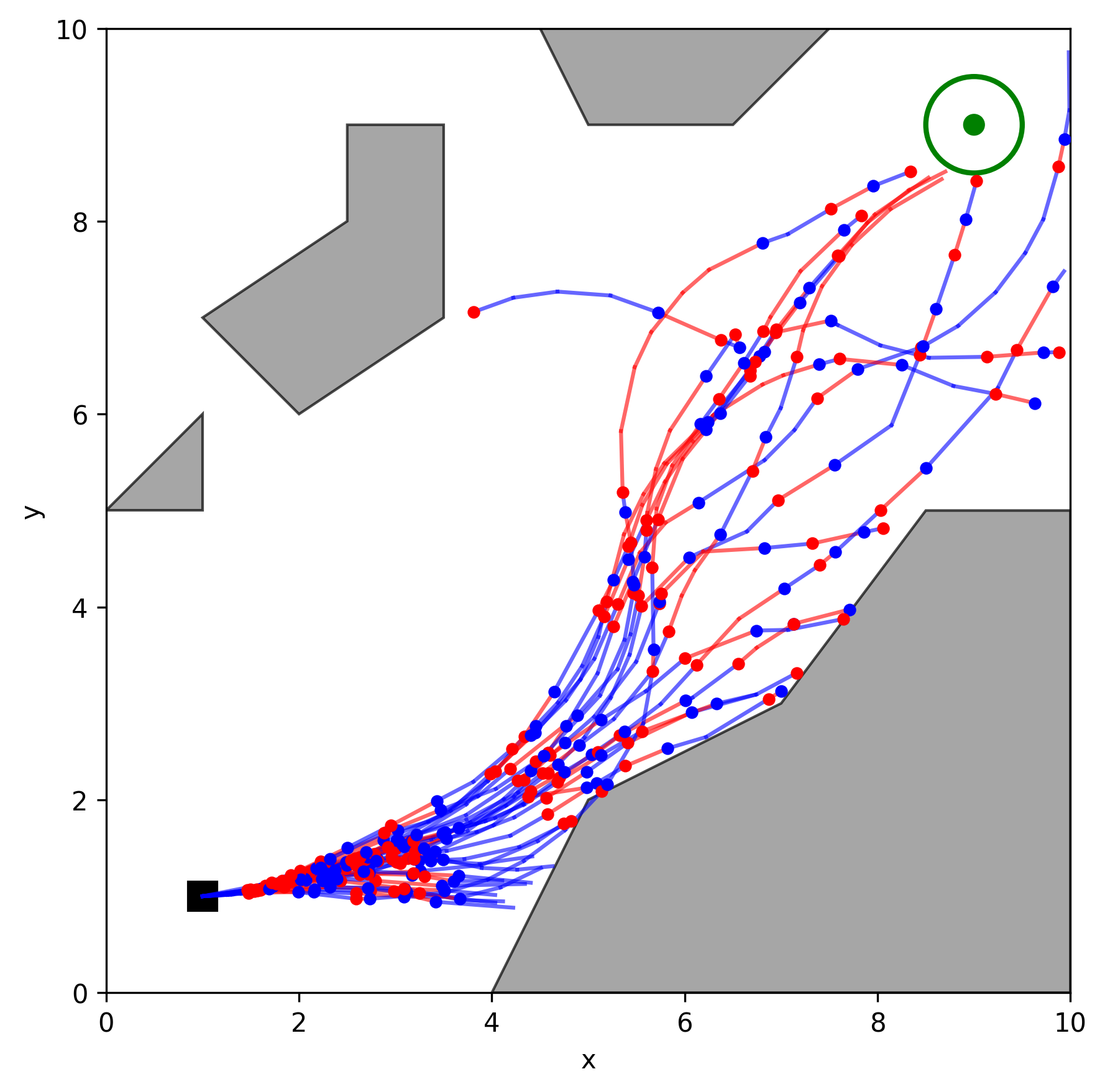
Figure 4. Medium environment, n = 1000.
Solution with SMRs
Using MDP helps us solve uncertainty because is a model for sequential decision making outcomes, meaning that it will evaluate the best possible action in each state. There are two distinct phases:
Learning phase
A roadmap was built by randomly sampling positions across the workspace. From each position, we simulate needle movements under different steering angles and compute where the needle might end up. Since tissue interactions make motion uncertain, we model transitions between states as *P(s'|s,a)* - the probability of reaching state *s'* when taking action *a* from state *s*. This creates a graph that captures possible needle trajectories throughout the environment.
Query phase
The query phase happens when we need to navigate from a start position to a target. We use value iteration to work backward from the goal, calculating optimal values for each state: *V(s) = max_a Σ P(s'|s,a)V(s')*. This recursive computation finds the best action for every state in our roadmap. The resulting policy *π(s) = argmax_a Σ P(s'|s,a)V(s')* tells us which steering angle gives the best chance of reaching the target from any position. The needle can then adapt in real-time as it encounters unexpected tissue properties or control errors.